Quad Trees
Sometimes, even when you come up with an elegant way to express surfaces for an environment you are rendering, it still isn't enough to handle other aspects of its use.
For example, a portal engine is a wonderful way of rendering mirrors and rooms in an inside environment without over-rendering. However, difficulties arise:
It's common in a game to set up structures that help reduce just how much data you parse to solve certain problems. It isn't practical to just try to render every mobile object and check for collisions between an object with every other object to be accurate.
Quad trees are basically square volumes that are meant to contain certain amounts of entities in each cell. By quickly determining which cells are relevent to what you are doing, you can limit the data you parse and keep your framerates up. Figuring out how far to render objects and what to check collisions against are two such uses for a quad tree. Octrees are just quadtrees in 3D (cubes instead of quads), but I'll talk about quadtrees here since the concepts are so similar.
A quad tree usually starts out with a single large quad that contains all of what you are working with (a underground map, for example). This large quad is then split into four parts (many times they are equal size, but they don't have to be). Each of those is split into four parts and get progressively smaller until the smallest cells contain a certain number of entities or are a certain explorable size.
Here's an example (pardon the crooked lines):
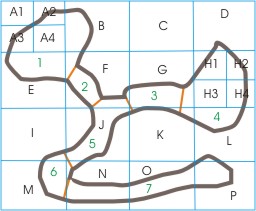
In this example, I've taken a simple cave map and split it according to explorable area. Cells A-P are the result of a large quad being split in 4, then all of those cells being split in 4. Any cell that contains more than a certain amount of explorable area is split again. Hence, cells A and H were split once more. I suppose I could have split E again, it was close. I also assumed that the map is defined as a portal map, so the orange lines illustrate where portals might be placed to help reduce surface rendering. Rooms are numbered in green. Notice that cell L has surfaces that are actually part of different rooms, quite far from each other. This may come into play later. Also, it isn't necessary that cells be split down the middle. It's up to you how you divide them.
The reason I split based on explorable area is the theory that through random placement and situations, there is a set number of maximum objects that could occupy a certain area. If an explorable area isn't very large, then a larger cell can be used to contain it, such as cell K, without any concern that too many objects will end up there. Cells A and H, however, might have ended up with more objects than we wanted in a single, parsable list.
As objects move around the map, I would keep track of which cell they are in (the location of their coordinate). If the objects have radius, I could also keep track of which cells they are touching. Also, I would list all the cells that each room (the spaces split by the the portals) are touching. For instance, room 1 touches cells A1-4, B, E and F.
When it comes to rendering, then, say I am only rendering room 1, because I'm facing a wall away from room 2. Any object touching A1-4, B, E or F are potentially visible objects in room 1, so I should render them as well. This handles the possibility of a large object poking through from room 2. If I wanted to further refine the rendering, I could ignore the cells that room 1 is touching and just render the cells I know I can see based on the viewpoint itself, and render the objects touching them. This would actually reduce the rendering more.
Note that if I am also rendering room 2, this method would attempt to render the large object a second time. So you'll need some sort of identifier or value to tell the renderer that the large object was already rendered and doesn't need to be rendered again (an incremented render ID representing the current map rendering is better than a time value, since you could be working with mirrors which would require that the object be rendered twice anyway - rendering the mirror image should be a separate render with its own ID that begins and completes before you render the "real" world).
For collisions, quadtrees also help reduce the parsing. Say a sphere is bouncing around in room 1. We could probably use the portal engine to detect its collisions with the walls, but since the large object in room 2 isn't placed in room 1, our sphere wouldn't be detected as colliding with it. That is, unless we include checking objects that are touching all the cells that the sphere touches along its path. This prevents the sphere from having to check collisions against every object on the map to be accurate, and prevents inaccuracies from only checking collisions against objects in the same room. You might be thinking that you could ignore using the quadtree and just check for objects that are close enough to the sphere to collide with it, but you would have to parse all of the objects in the map list to determine that. Parsing only the objects listed in the relevent cells avoids looking at too much data to get an accurate result. The one difficulty I see is that the sphere could check for collisions against the same object multiple times, but this problem is solved by using another incremental ID as a tag to prevent multiple checks on the same object. As an option, you could also list the walls that touch each cell and bypass using the portal engine structure to check for wall collisions.
Now let's look at cell L. It touches rooms that are far from each other in the exploration sense. A ball bouncing around in room 4, then, might end up checking for collisions against objects in room 7. This doesn't make any sense, but that's what happens sometimes with quadtrees. Even though a collision isn't realistically possible, at least the parsing is kept to a minimum, especially since the amount of space in room 7 that cell L contains is very small and unlikely to contain very many objects. As for rendering, objects in room 7 might be rendered even though the viewpoint is in room 4, but the rendering of the walls in room 4 should sufficiently occlude them. If the objects in room 7 generate sounds, it will be up to other parts of your engine (perhaps evaluating distance to the object based on the portal path to get there) to determine if it can actually be heard.
So, it appears that quad trees (and the corresponding octrees in 3D) can sufficiently help with rendering mobile objects and collision detections between mobile objects, and help keep the parsing to a minimum. Evaluating whether or not to split a cell helps to keep the complexity of the quadtree structure to a minimum as well. After that, maintaining lists of which cells that objects are touching is only necessary when they are placed or moved, and since the coordinates of the cells are based on the world axes, comparisons to determine containment are fast.
Storage challenge
There are two concepts with using a quad tree:
There are times when you need to know all the cells an object touches, and there are times when you need to know all the objects contained within a specific cell. These two lists must be contained in parallel to be accurate. As I know more about this, I'll list my findings here. What I know at this point is that it is crucial that lists be contained at both levels to keep parsing to a minimum.
What I'll probably do is develop a demo app in Visual Basic that has many, many balls bouncing around in a box, with the box split into quads, and checking collisions against each other. Then I'll try it without the quadtree, with a quadtree, and with varying degrees of splitting in the quad tree to see if too much splitting is a problem (which I expect it will be).
Developer notes
As I prepare to develop the collision demo, I've run into a problem. When it comes to rendering, the quadtree algorithm isn't too much of a problem, because I can determine which cells an object touches in its final position and use that information to decide what to render. For collisions, however, it gets a little more complicated. I suppose it depends on the real methodology of the collision.
Consider a game of billiards, where it's important to find the first collision, move everything up to that time, apply the collision, and continue the algorithm (re-evaluating cells touched for balls that change direction) until that tick's game time is consumed. For a game of billiards, that kind of accuracy is necessary. However, for a simpler game such as a space sim or adventure game, it doesn't really matter that the collision detection be so hyper-accurate:
All objects could be moved to their final position, then collisions checked on their final state, or projected forward from their start position in that time frame and collisions checked along their paths. The first method allows us to quickly determine which cells objects are touching and parse those lists. The second method requires us to determine which cells objects touch throughout their path (the quickest way is to build a rectangle that represents the bounds of the square an object occupies as it moves, diagonal movement generating the largest and most wasteful rectangle). When a collision is detected, I just apply the changes and don't bother checking collisions with those objects anymore. They might end up going through each other occasionally because of this, but it's not a big deal in many cases.
I'll have to look at the advantages and disadvantages of each. Either way, there's a lot of initial list building before the collision detection can even begin. I don't want to re-calculate touched cells for objects that don't need it (for instance, those that didn't move), and I need to be able to quickly remove or add an object reference to any given cell's list. At first glance, it appears I may not need to list all the cells an object touches, only list the objects touching a cell (edit: I do need cells listed at the ball level for quick updates - see below).
Demo results
I set up a demo with 400 balls of various radii bouncing around in a 16x16 square.
I did need to keep track of cells a ball touches and balls touched by a cell. Every tick, I figured out the square a ball would occupy throughout its movement, and listed all the cells that square touched, and at the cell level, stored all the squares that touch it. I only applied updates to the cell lists as balls moved (which is why I required ball lists at the cell level and cell lists at the ball level). Split 4 times, there were maybe 1-2 balls in a cell at any given time. Split 3 times, probably 6-7. (Dividing 400 by 256 and 64, respectively)
Clearly, as the quadtree became more and more split, the data preparation became more complex, requiring deeper parses, ultimately slowing down the algorithm. So you can, in fact, go too far with quad tree splitting. However, with a 3x frame rate increase (2x in release), it's definitely worth using as long as you can find a balance. And if your environment is mostly unmoving so that cell lists don't have to be evaluated so much, the algorithm would be even faster.
So, quad trees can be used to speed up collision detection as well as assist in the completeness of rendering.
Experimenting further, I increased the box to 32x32 and quadrupled the ball amount and got similar results. A 4-split quadtree performed the best, and gave a 4x frame rate increase above simple ball-ball testing (95 and 24). A 5-split performed very close to the 4-split.
Another note: At first I just watched for ball indices to be less than the other for collision detection (to make it similar to the ball-ball collision without the quadtree), but that isn't enough to avoid the same collision detection happening twice (ball j could appear in multiple cell lists and be checked against ball i more than once as a result), so I put in the collision ID to prevent the extra checks. It didn't even speed up the algorithm, but it does help prevent inaccuracies if you want to avoid problems caused by checking the same collision twice. After adding some counter variables, I found that putting in the ID prevented about 8% of the collision checks.
Octrees
I applied what I learned here to octrees and found out a few things:
A quick hint
If you want to split a quad or octree based on maximum explorable area per cell, what you could do is just submit the bounding box for every room in your map. Diagonal rooms would cause wasteful splitting because the bounding box doesn't accurately represent the room's actual explorable area, but you could compensate by increasing the allowed explorable area a little. It beats writing a routine to accurately calculate the area of a room. Bleh.
Another way to implement a quadtree
Poking around at GameDev.net, I found a discussion on quadtrees and collision detection. One programmer mentioned to store an object in the smallest possible cell that entirely contains it, and check collisions against all objects as the logic looks for the cell that contains it, and check collisions against every object deeper in that cell. I may attempt that. In my logic above, the only returnable cell references are at the deepest ends. This algorithm allows objects to be stored higher up. An incremented ID would tell the cell to empty its object list for insertion of a new object so that I wouldn't have to empty all the lists after I'm done. I may do that anyway.